Abstract
Effective exploration is a crucial challenge in deep reinforcement learning. Behavioral priors have been shown to tackle this problem successfully, at the expense of reduced generality and restricted transferability. We thus propose temporal priors as a non-Markovian generalization of behavioral priors for guiding exploration in reinforcement learning. Critically, we focus on state-independent temporal priors, which exploit the idea of temporal consistency and are generally applicable and capable of transferring across a wide range of tasks. We show how dynamically sampling actions from a probabilistic mixture of policy and temporal prior can accelerate off-policy reinforcement learning in unseen downstream tasks. We provide empirical evidence that our approach improves upon strong baselines in long-horizon continuous control tasks under sparse reward settings.
Results
Training a state-free prior
State-free priors can be trained on offline task-agnostic demonstrations (e.g. reaching random positions in an uncluttered environment, as on the left) and used to enable or accelerate RL on unseen downstream tasks. While any conditional generative model which allows sampling is suitable, we rely on Real NVP Flow.
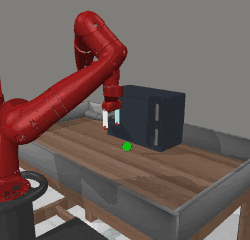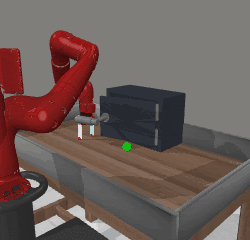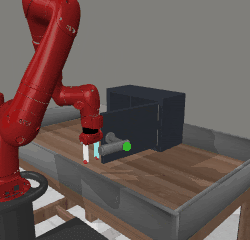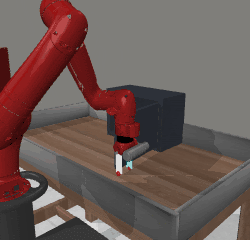
SFP (top) and SAC (bottom) in downstream learning
reach

window-open


door-open